 客服热线:
客服热线:
历史表明,网络安全威胁随着新的技术进步而增加。关系数据库带来了SQL注入攻击,Web脚本编程语言助长了跨站点脚本攻击,物联网设备开辟了创建僵尸网络的新方法。而互联网打开了潘多拉盒子的数字安全弊病,社交媒体创造了通过微目标内容分发来操纵人们的新方法,并且更容易收到网络钓鱼攻击的信息,比特币使得加密ransowmare攻击成为可能。类似的威胁网络安全的方法还在不断产生。关键是,每项新技术都会带来以前难以想象的新安全威胁。
最近,深度学习和神经网络在支持各种行业的技术方面变得非常突出。从内容推荐到疾病诊断和治疗以及自动驾驶,深度学习在做出关键决策方面发挥着非常重要的作用。
现在我们所面临的问题是,知道神经网络和深度学习算法所特有的安全威胁是什么?在过去几年中,我们已经看到了恶意行为者开始使用深度学习算法的特征和功能来进行网络攻击的示例。虽然我们仍然不知道何时会出现大规模的深度学习攻击,但这些例子可以说成是将要发生事情的序幕。
你应该知道
深度学习和神经网络可用于放大或增强已存在的某些类型的网络攻击。例如,你可以使用神经网络在网络钓鱼诈骗中复制目标的写作风格。正如DARPA网络大挑战在2016年所展示的那样,神经网络也可能有助于自动发现和利用系统漏洞。但是,如上所述,我们专注于深度学习所特有的网络安全威胁,这意味着在深度学习算法进入我们的软件之前,它们不可能存在。我们也不会涵盖算法偏见和神经网络的其他社会和政治含义,如操纵选举。要研究深度学习算法的独特安全威胁,首先必须了解神经网络的独特特征。
什么使深度学习算法独一无二?

深度学习是机器学习的一个子集,机器学习是一个人工智能领域,其中软件通过检查和比较大量数据来创建自己的逻辑。机器学习已存在很长时间,但深度学习在过去几年才开始流行。
人工神经网络是深度学习算法的基础结构,大致模仿人类大脑的物理结构。与传统的软件开发方法相反,传统的程序员精心编写定义应用程序行为的规则,而神经网络通过阅读大量示例创建自己的行为规则。
当你为神经网络提供训练样例时,它会通过人工神经元层运行它,然后调整它们的内部参数,以便能够对具有相似属性的未来数据进行分类。这对于手动编码软件来说是非常困难的,但神经网络却非常有用。
例如,如果你使用猫和狗的样本图像训练神经网络,它将能够告诉你新图像是否包含猫或狗。使用经典机器学习或较旧的AI技术执行此类任务非常困难,一般很缓慢且容易出错。计算机视觉、语音识别、语音转文本和面部识别都是由于深度学习而取得巨大进步的。
但神经网络在保证准确性的同时,失去的却是透明度和控制力。神经网络可以很好地执行特定任务,但很难理解数十亿的神经元和参数是如何进行网络决策的。这被称为“AI黑匣子”问题。在许多情况下,即使是创建深度学习算法的人也很难解释他们的内部工作原理。
总结深度学习算法和神经网络两个与网络安全相关的特征:
他们过分依赖数据,这意味着他们与他们训练的数据一样好(或坏)。它们是不透明的,这意味着我们不知道它们如何起作用。接下来,我们看看恶意行为者如何利用深度学习算法的独特特征来进行网络攻击。
对抗性攻击

labsix的研究人员展示了一只改良的玩具龟如何欺骗深度学习算法将其归类为步枪
神经网络经常会犯错,这对人类来说似乎是完全不合逻辑甚至是愚蠢的。例如,去年,英国大都会警察局用来检测和标记虐待儿童图片的人工智能软件错误地将沙丘图片标记为裸体。在另一个案例中,麻省理工学院的学生表示,对玩具龟进行微小改动会导致神经网络将其归类为步枪。
这些错误一直伴随着神经网络而存在。虽然神经网络通常会输出与人类产生的结果非常相似的结果,但它们并不一定经历相同的决策过程。例如,如果你只用白猫和黑狗的图像训练一个神经网络,它可能会优化其参数,根据动物的颜色而不是它们的物理特征对动物进行分类。
对抗性的例子,导致神经网络产生非理性错误的输入,强调了AI算法和人类思维的功能之间的差异。在大多数情况下,可以通过提供更多训练数据并允许神经网络重新调整其内部参数来修复对抗性示例。但由于神经网络的不透明性,找到并修复深度学习算法的对抗性示例可能非常困难。
恶意行为者可以利用这些错误对依赖深度学习算法的系统进行对抗性攻击。例如,在2017年,密歇根州华盛顿大学以及加州大学伯克利分校的研究人员表示,通过进行小幅调整来停止标志,他们可以使自动驾驶汽车的计算机视觉算法不可见。这意味着黑客可以强迫自动驾驶汽车以危险的方式行事并可能导致事故。如下面的例子所示,没有人类驾驶员不会注意到“被黑”的停车标志,但神经网络可能完全失明。

在另一个例子中,卡内基梅隆大学的研究人员表示,他们可以欺骗面部识别系统背后的神经网络,通过佩戴一副特殊的眼镜将一个人误认为另一个人。这意味着攻击者可以使用对抗攻击来绕过面部识别身份验证系统。

卡内基梅隆大学的研究人员发现,通过戴上特殊眼镜,他们可以欺骗面部识别算法
对抗性攻击不仅限于计算机视觉,它们还可以应用于依赖神经网络和深度学习的语音识别系统。加州大学伯克利分校的研究人员涉及了一种概念验证,在这种概念验证中,他们操纵音频文件的方式会让人耳不被注意,但会导致AI转录系统产生不同的输出。例如,这种对抗性攻击可用于以在播放时向智能扬声器发送命令的方式来改变音乐文件,播放文件的人不会注意到文件包含的隐藏命令。
目前,只在实验室和研究中心探索对抗性攻击。暂时还没有证据表明发生过对抗性攻击的真实案例。发展对抗性攻击与发现和修复它们一样困难,因为对抗性攻击也非常不稳定,它们只能在特定情况下工作。例如,视角或照明条件的微小变化可以破坏对计算机视觉系统的对抗性攻击。
但它们仍然是一个真正的威胁,对抗性攻击将变得商业化只是时间问题,正如我们在深度学习的其他不良用途中看到的那样。
但我们也看到人工智能行业也正在努力帮助减轻对抗深度学习算法的对抗性攻击的威胁。在这方面可以提供帮助的方法之一是使用生成对抗网络(GAN)。GAN是一种深度学习技术,它使两个神经网络相互对抗以产生新数据。第一个网络即生成器创建输入数据,第二个网络,即分类器,评估由生成器创建的数据,并确定它是否可以作为特定类别传递。如果它没有通过测试,则生成器修改其数据并再次将其提交给分类器。两个神经网络重复该过程,直到生成器可以欺骗分类器认为它创建的数据是真实的。GAN可以帮助自动化查找和修补对抗性示例的过程。
另一个可以帮助强化神经网络抵御对抗性攻击的趋势是创建可解释的人工智能。可解释的AI技术有助于揭示神经网络的决策过程,并有助于调查和发现对抗性攻击的可能漏洞。一个例子是RISE,一种由波士顿大学研究人员开发的可解释的人工智能技术。RISE生成热图,表示输入的哪些部分对神经网络产生的输出有贡献。诸如RISE之类的技术可以帮助在神经网络中找到可能存在问题的参数,这些参数可能使它们容易受到对抗性攻击。
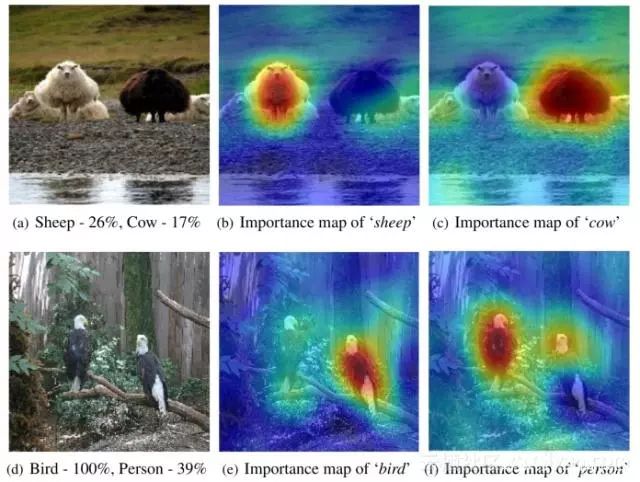
RISE产生的显着图的例子
数据中毒(Data poisoning)
虽然对抗性攻击在神经网络中可以发现并解决相关问题,但数据中毒通过利用其过度依赖数据在深度学习算法中产生问题行为。深度学习算法没有道德、常识和人类思维所具有的歧视的概念。它们只反映了他们训练的数据隐藏的偏见和趋势。2016年,推特用户向微软部署的人工智能聊天机器人提供仇恨言论和种族主义言论,在24小时内,聊天机器人变成了纳粹支持者和大屠杀否认者,然后毫不犹豫地发出了恶意评论。
由于深度学习算法仅与其数据质量保持一致,因此为神经网络提供精心定制的训练数据的恶意行为者可能会导致其表现出有害行为。这种数据中毒攻击对于深度学习算法特别有效,这些算法从公开可用或由外部参与者生成的数据中提取训练。
已经有几个例子说明刑事司法、面部识别和招募中的自动化系统由于其训练数据中的偏差或缺点而犯了错误。虽然这些例子中的大多数是由于困扰我们社会的其他问题而在我们的公共数据中已经存在的无意错误,但没有什么能阻止恶意行为者故意毒害训练神经网络的数据。
例如,考虑一种深度学习算法,该算法监视网络流量并对安全和恶意活动进行分类。这是一个无监督学习的系统。与依赖于人类标记的示例来训练其网络的计算机视觉应用相反,无监督的机器学习系统通过未标记的数据来仔细查找共同的模式,而无需接收关于数据所代表的具体指令。
例如,AI网络安全系统将使用机器学习为每个用户建立基线网络活动模式。如果用户突然开始下载比正常基线显示的数据多得多的数据,系统会将其归类为潜在的恶意意图人员。但,具有恶意意图的用户可以通过以小增量增加他们的下载习惯来欺骗系统以慢慢地“训练”神经网络以认为这是他们的正常行为。
数据中毒的其他示例可能包括训练面部识别认证系统以验证未授权人员的身份。去年,在Apple推出新的基于神经网络的Face ID身份验证技术之后,许多用户开始测试其功能范围。正如苹果已经警告的那样,在某些情况下,该技术未能说出同卵双胞胎之间的区别。
但其中一个有趣的失败是两兄弟的情况,他们不是双胞胎,看起来不一样,年龄相差多年。这对兄弟最初发布了一段视频,展示了如何用Face ID解锁iPhone X.但后来他们发布了一个更新,其中他们表明他们实际上通过用他们的面部训练其神经网络来欺骗Face ID。其实这是一个无害的例子,但很容易看出同一模式如何为恶意目的服务。
由于神经网络不透明且开发人员不创建规则,因此很难调查并发现用户可能故意对深度学习算法造成的有害行为。
基于深度学习的恶意软件
今年早些时候,IBM的研究人员引入了一种新的恶意软件,它利用神经网络的特性针对特定用户隐藏恶意负载,有针对性的攻击以前是拥有大量计算和情报资源的国家和组织。
但是,由IBM开发的概念验证恶意软件DeepLocker表明,此类攻击可能很快成为恶意黑客的正常操作方式。DeepLocker已将其恶意行为和有效负载嵌入到神经网络中,以将其隐藏在端点安全工具之外,后者通常会在应用程序的二进制文件中查找签名和预定义模式。
DeepLocker的另一个特点是使用神经网络为其有效载荷指定特定目标。为了显示基于深度学习的恶意软件的破坏性功能,IBM研究人员为DeepLocker提供了勒索软件病毒,并将其嵌入到视频会议应用程序中。

同时,恶意软件的开发人员在通过网络摄像头看到特定用户的面部时,可以训练神经网络来激活有效负载。由于恶意软件嵌入在视频会议应用程序中,因此它可以合法访问网络摄像头的视频源,并能够监控应用程序的用户。一旦目标在摄像机前显示他们的脸,DeepLocker就会释放勒索软件并开始加密用户计算机上的所有文件。
黑客将能够使用DeepLocker等恶意软件根据他们的性别和种族,用特定深度学习算法来定位特定用户或群体。我们尚未了解深度学习算法和神经网络的网络安全威胁的规模。创建DeepLocker的研究人员表示,他们并不确定此类恶意软件是否已经在黑客放弃。未来在神经网络领域面临的网络安全问题,还存在诸多不确定性!
组委会联系方式:
电话:028-85253110


